🟡 最少到最多提示过程
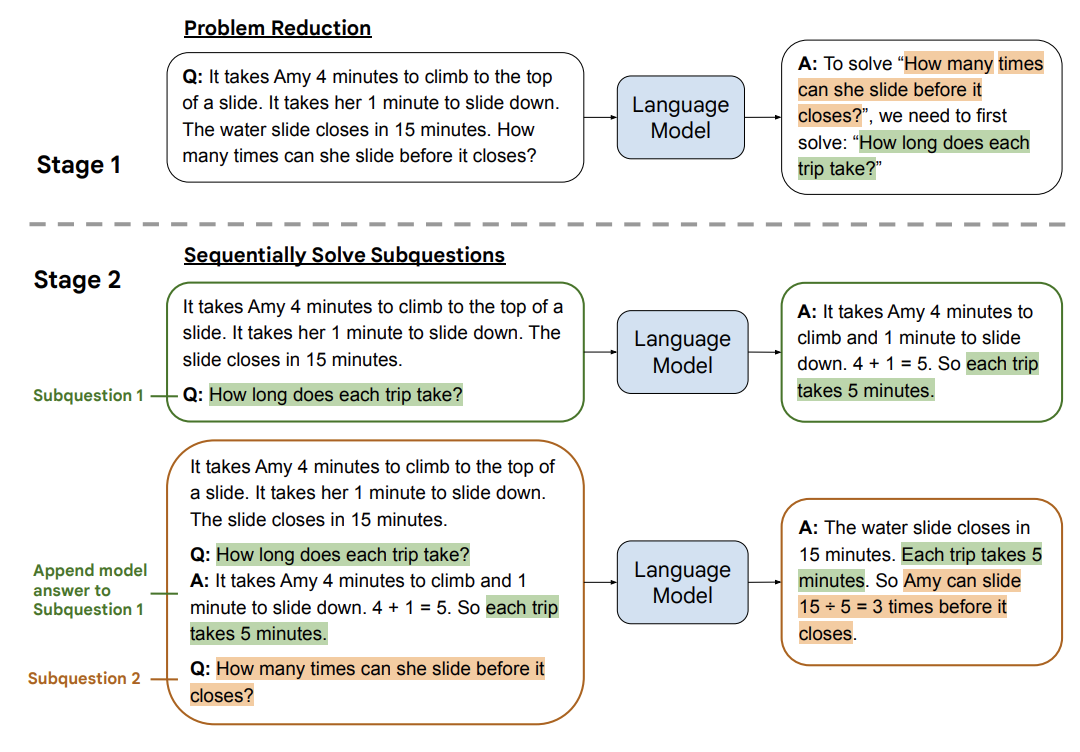
最少到最多提示过程 (Least to Most prompting, LtM)1 将 思维链提示过程 (CoT prompting) 进一步发展,首先将问题分解为子问题,然后逐个解决。它是受到针对儿童的现实教育策略的启发而发展出的一种技术。
与思维链提示过程类似,需要解决的问题被分解成一组建立在彼此之上的子问题。在第二步中,这些子问题被逐个解决。与思维链不同的是,先前子问题的解决方案被输入到提示中,以尝试解决下一个问题。
示例:回复客户咨询
让我们问一个稍微复杂的客服问题:
这个回答是错误的(目前还在退货时间内),那我们来将问题分解为子问题试试:
让我们试着解决第一个子问题:
仅仅通过解决第一个子问题,我们就能解决整个问题。如果 GPT-3 没有立即给出答案,我们可以解决下一个子问题,直到它返回答案。值得注意的是,我们使用 让我们一步一步来 的提示短语。这个提示不是必须的,但对于这个例子来说效果很好。
示例:字符连接
LtM 最初是使用 few-shot 提示的方式引入的,而不是显式指令将问题分解为多个步骤(如上所示)。除此之外,有时也可以使用单一提示而不是提示链来实现它。让我们来看看字符连接的尾字问题2,例如给定输入词语 思考、机器,则输出应为 考器。
第一次尝试:标准提示
即使使用更先进的模型(如 text-davinci-003),标准提示与 few-shot 示例的表现也非常糟糕。
第二次尝试:思维链
思维链的表现比标准提示好得多。这是因为它现在允许模型考虑自己提取每个单词的最后一个字母,将复杂性降低到分组已经收集的字母的行为。然而,这种方法在更长的输入下也可能慢慢出现问题。
第三次尝试:LtM(单一提示)
使用 LtM,我们通过重新表述先前串联的结果来增强思维链的概念。这种做法使得每个步骤变的简单,即每次只需要连接一个字符。这种方法带来了非常好的效果,12 个乃至更多的词都能得到正确结果。
这种方法看起来与思维链非常相似,但在概念上大有不同。在这里,每一步都引入了上一步连接的结果。例如,在“思考、机器、学习”的这个例子种,它不会单独连接字符“考”,“器”,“习”,而是连接“考”和“器”,然后连接“考器”和“习”。由于重新引入了上一步的结果,模型现在可以推广到更长的链,因为它每一步都带着增量结果,同时单步骤内只需要做很少的工作。
(译注:该例子使用了 '|' 而非 ',',是因为中文的逗号经常不被识别为分隔符)。结论
在具有 12 个词的字符问题上,思维链的准确率为 34%,而 LtM 的准确率为 74%(该论文使用 text-davinci-002 作为模型)(译注:上面的示例因为翻译成了中文,所以准确率与原文中的值应该不同)。
示例:组合泛化问题(compositional generalization) (SCAN)
SCAN 基准测试3要求模型将自然语言转换为动作序列。例如,句子 “run left and walk twice” 将被翻译为 “TURN_LEFT + RUN + WALK * 2”。当面对训练集中长度更长的序列时,语言模型的表现尤其差。
第一次尝试:标准提示
使用简单的标准提示,text-davinci-003 的表现非常出色,但仍然失败了。
(译注:该示例如果翻译成中文,无法复现效果,因此保持原文)
第二次尝试:LtM,第一步 - 缩减
在这里,我们使用两个不同的提示。第一个提示用于将输入问题缩减为一个步骤序列。第二个提示用于将这个缩减后的步骤序列映射到实际的操作中。
这两个提示都相当长,因而使用压缩的 Python 符号表示操作,以节省标记(tokens)。
第一步将自然语言描述分解为更明确但仍类似人类的语言。这将有助于映射步骤按顺序解决问题。 例如,“jump around left twice” 被简化为 “jump left” -> TURN_LEFT + JUMP 和 “jump around left” -> (TURN_LEFT + JUMP) * 4。同样,减少步骤是用来解释重复概念(twice、thrice 等)的。
第二次尝试:LtM,第二步 - 映射
在第二步中,我们使用缩减过的结果,并再次使用相当长的提示(14个案例)将简化的自然语言描述转换为一系列操作。
在这里,我们注入第一步的输出:
"jump around left twice" can be solved by: "jump left", "jump around left", "jump around left twice". "walk opposite left thrice" can be solved by: "walk opposite left", "walk opposite left thrice". So, "jump around left twice after walk opposite left thrice" can be solved by: "jump left", "jump around left", "jump around left twice", "walk opposite left", "walk opposite left thrice".
到 LLM 中。
结论
LtM 带来了多项提升:
- 相对于思维链提高了准确性
- 在难度高于提示的问题上提升了泛化能力
- 在组合泛化方面的性能得到了显著提高,特别是在SCAN基准测试3中
使用 text-davinci-002(论文中使用的模型)的标准提示解决了 6% 的 SCAN 问题,而 LtM 提示则取得了惊人的 76% 的成功率。在 code-davinci-002 中,结果更为显著,LtM 达到了 99.7% 的成功率。
- Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., & Chi, E. (2022). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. ↩
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. ↩
- Lake, B. M., & Baroni, M. (2018). Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks. https://doi.org/10.48550/arXiv.1711.00350 ↩