🟡 Prompt Ensembling
Prompt ensembling is the concept of using multiple different prompts to try to answer the same question. There are many different approaches to this.
DiVeRSe
DiVeRSe1 ("Diverse Verifier on Reasoning Steps") is a method that improves the reliability of answers in a threefold manner. It does this by 1) using multiple prompts to generate diverse completions, 2) using a verifier to distinguish good answers from bad answers, and 3) using a verifier to check the correctness of reasoning steps.

Diverse Prompts
DiVeRSe uses 5 different prompts a given input. To construct each prompt, they randomly sample a few exemplars from the training set. Here is an example of one such few-shot prompt (k=2), with exemplars taken from the GSM8K benchmark2. In practice, DiVeRSe uses 5 exemplars in prompts for this benchmark.
Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
A: Natalia sold 48/2 = 24 clips in May.
Natalia sold 48+24 = 72 clips altogether in April and May.
#### 72
Q: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?
A: Weng earns 12/60 = $0.2 per minute.
Working 50 minutes, she earned 0.2 x 50 = $10.
#### 10
Q: Betty is saving money for a new wallet which costs $100. Betty has only half of the money she needs. Her parents decided to give her $15 for that purpose, and her grandparents twice as much as her parents. How much more money does Betty need to buy the wallet?
A:
After generating 5 different prompts like above, DiVeRSe samples 20 reasoning paths for each (temperature = 0.5). Here are a few example completions of the above prompt. Note that the answers are not always correct.
Betty has 0.5*100 = $50.
Then she gets 15 more = $65.
Then she gets 2*15 = $90.
She needs 100-90 = $10 more.
#### 10
A: Betty has 0.5*100 = $500.
Then she gets 15 more = $650.
Then she gets 2*15 = $900.
She needs 100-90 = $1000 more.
#### 1000
At this point, DiVeRSe has generated 100 different completions.
Voting Verifier
Now, we could just take the majority answer, like Self-Consistency3 does.
However, DiVeRSe proposes a much more complicated method, which they call a voting verifier.
At test time, using the voting verifier is a two step process. First, the verifier (a neural network) assigns a 0-1 score to each completion based on how likely it is to be correct. Then, the 'voting' component sums all of the scores over different answers and yields the final answer.
Example
Here is a small example. Say we have the following completions for the prompt What is two plus two?:
4
two + 2 = 5
I think 2+2 = 6
two plus two = 4
It is 5
The verifier will read each completion and assign a score to it. For example, it might assign the scores: 0.9, 0.1, 0.2, 0.8, 0.3 respectively. Then, the voting component will sum the scores for each answer.
score(4) = 0.9 + 0.8 = 1.7
score(5) = 0.1 + 0.3 = 0.4
score(6) = 0.2
The final answer is 4, since it has the highest score.
But how is the verifier trained?
The verifier is trained with a slightly complex loss function, which I will not cover here. Read section 3.3 of the paper for more details1.
Ask Me Anything (AMA) Prompting
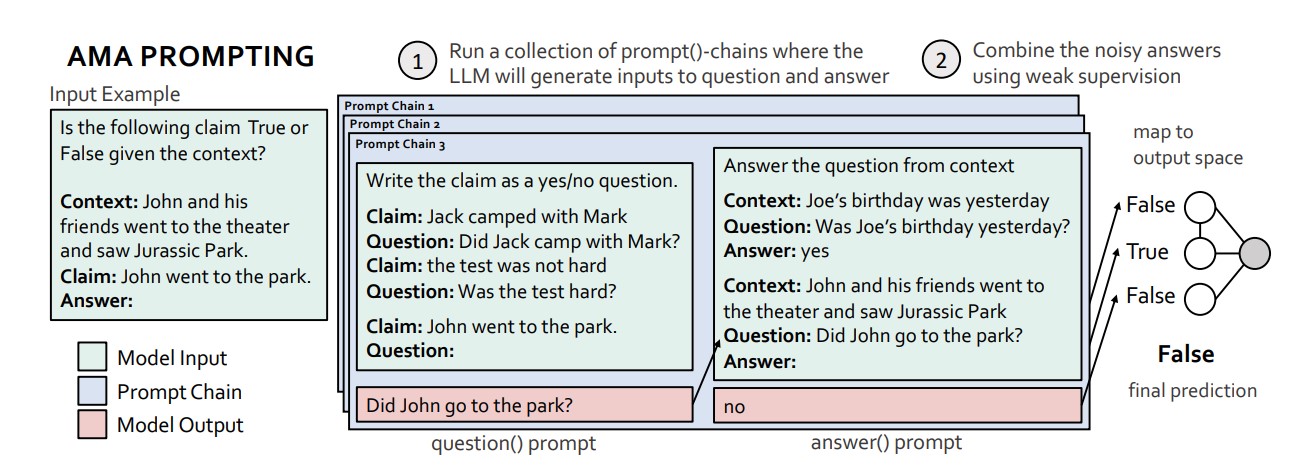
Ask Me Anything (AMA) prompting4 is a similar approach to DiVeRSe. However, both its multiple prompt step and its answer aggregation step differ signifigantly. The core idea of AMA is to use a LLM to generate multiple prompts, instead of just using different few-shot exemplars.
Multiple Prompts
AMA shows that you can take a question and reformat it in multiple ways to create different prompts. For example, say you are scraping a bunch of websites for information on animals and want to only record ones that live in North America. Let's construct a prompt to determine this.
Given the following passage from Wikipedia:
The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
You can format this task into a prompt like so:
Is the following claim True or False given the context?
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
Claim: This animal lives in North America
Answer:
This is a bit of an odd formulation. Why not just use the following simpler prompt?
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
Question: Does this animal lives in North America?
Well, by formulating the question in this special way, we can generate different prompts.
Our first step here will be to take the claim This animal lives in North America and reformat it into different questions, which are basically asking the same thing. To do this, we will pass the claim through prompts like those in the below image.

This might output:
- Was the animal living in North America?
- Does the animal live in North America?
- Where does the animal live?
The idea behind this is to create different views of the task. We then apply each to the given context like so:
Context: The Kermode bear, sometimes called the spirit bear (Ursus americanus kermodei), is a subspecies of the American black bear and lives in the Central and North Coast regions of British Columbia, Canada.
Question: Was the animal living in North America?
Then, we can generate answers for each:
Yes it wasYes it doesNorth America
These are intermediate answers. We need to map them to task labels (e.g. Yes or No).
We can do this by passing the intermediate answers through a prompt like the following:
Select the correct category.
"Categories":
- Yes, North America
- No, not North America
"Yes it was" fits category:
Now we can get our output answers.
Yes, North AmericaYes, North AmericaYes, North America
Here, they all agree, so we can just take the first answer. However, if they disagreed, we could use the AMA aggregation step to get a final answer.
Answer Aggregation
AMA uses a very complicated strategy for aggregating answers (more so than DiVeRSe) instead of simply taking the majority answer. To understand why the majority answer may be a poor choice, consider two of the questions we generated before:
- Was the animal living in North America?
- Does the animal live in North America?
They are extremely similar, so will likely generate the same result. Since the questions are so similar, they will effectively bias the end result. To deal with this, AMA relies on weak supervision and complex mathematics in order to estimate dependencies between different prompts it creates, and then uses this to weight them appropriately.
So, for the three questions we generated, it might assign weights of 25%, 25%, and 50%, since the first two are so similar.
Although AMA's aggregation strategy is powerful, it is so complicated that I will not cover it here. Read section 3.4 of the paper for more details4.
Results
With this prompting strategy, AMA is able to use GPT-J-6B5 to outperform GPT-3.
AMA is better on questions where given context contains the answer.
Takeaways
Ensembling methods are very powerful. They can be used to improve the performance of any model, and can be used to improve the performance of a model on a specific task.
In practice, majority voting should be your go to strategy.
- Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J.-G., & Chen, W. (2022). On the Advance of Making Language Models Better Reasoners. ↩
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. ↩
- Mitchell, E., Noh, J. J., Li, S., Armstrong, W. S., Agarwal, A., Liu, P., Finn, C., & Manning, C. D. (2022). Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference. ↩
- Arora, S., Narayan, A., Chen, M. F., Orr, L., Guha, N., Bhatia, K., Chami, I., Sala, F., & Ré, C. (2022). Ask Me Anything: A simple strategy for prompting language models. ↩
- Wang, B., & Komatsuzaki, A. (2021). GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax. https://github.com/kingoflolz/mesh-transformer-jax ↩